
AMD Dual-Fiji “Gemini” Video Card Delayed To 2016, Aligned With VR Headset Launches
But first, let’s get to the big news for the day: the status of AMD’s dual-GPU Fiji card, codename Gemini. As our regular readers likely recall, back at AMD’s Fiji GPU launch event in June, the company showed off four different Fiji card designs. These were the Radeon R9 Fury X, the R9 Fury, the R9 Nano, and finally the company’s then-unnamed dual-GPU Fiji card (now known by the codename Gemini). At the time Gemini was still in development – with AMD showing off an engineering sample of the board – stating that they expected the card to be released in the fall of 2015.
| AMD GPU Specification Comparison | ||||||
| AMD Radeon R9 Fury X | AMD Radeon R9 Fury | AMD Radeon R9 Nano | AMD Gemini (Dual Fiji Card) |
|||
| Stream Processors | 4096 | 3584 | 4096 | 2 x ? | ||
| Texture Units | 256 | 224 | 256 | 2 x ? | ||
| ROPs | 64 | 64 | 64 | 2 x 64 | ||
| Boost Clock | 1050MHz | 1000MHz | 1000MHz | ? | ||
| Memory Clock | 1Gbps HBM | 1Gbps HBM | 1Gbps HBM | ? | ||
| Memory Bus Width | 4096-bit | 4096-bit | 4096-bit | 2 x 4096-bit | ||
| VRAM | 4GB | 4GB | 4GB | 2 x 4GB | ||
| FP64 | 1/16 | 1/16 | 1/16 | 1/16 | ||
| TrueAudio | Y | Y | Y | Y | ||
| Transistor Count | 8.9B | 8.9B | 8.9B | 2 x 8.9B | ||
| Typical Board Power | 275W | 275W | 175W | ? | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | TSMC 28nm | ||
| Architecture | GCN 1.2 | GCN 1.2 | GCN 1.2 | GCN 1.2 | ||
| GPU | Fiji | Fiji | Fiji | Fiji | ||
| Launch Date | 06/24/15 | 07/14/15 | 09/10/15 | 2016 | ||
| Launch Price | $649 | $549 | $649 | (Unknown) | ||
However since that original announcement we haven’t heard anything further about Gemini, with AMD/RTG more focused on launching the first three Fiji cards. But with today marking the start of winter, RTG has now officially missed their original launch date for the card.

With winter upon us, I reached out to RTG last night to find out the current status of Gemini. The response from RTG is that Gemini has been delayed to 2016 to better align with the launch of VR headsets.
The product schedule for Fiji Gemini had initially been aligned with consumer HMD availability, which had been scheduled for Q415 back in June. Due to some delays in overall VR ecosystem readiness, HMDs are now expected to be available to consumers by early Q216. To ensure the optimal VR experience, we’re adjusting the Fiji Gemini launch schedule to better align with the market.
Working samples of Fiji Gemini have shipped to a variety of B2B customers in Q415, and initial customer reaction has been very positive.
And as far as video card launches go – and this will be one of the oddest things I’ve ever said – I have never before been relieved to see a video card launch delayed. Why? Because of the current state of alternate frame rendering.

Stepping to the side of the Gemini delay for the moment, I want to talk a bit about internal article development at AnandTech. Back in November when I was still expecting a November/December launch for Gemini, I began doing some preliminary planning for the Gemini review. What cards/setups we’d test, what games we’d use, resolutions and settings, etc. The potential performance offered by dual-GPU cards (and multi-GPU setups in general) means that to properly test them we need to put together some more strenuous tests to fit their performance profile, and we also need to assemble scenarios to evaluate other factors such as multi-GPU scaling and frame pacing consistency. What I found for testing disappointed me.
To cut right to the chase, based on my preliminary planning, things were (and still are) looking troubled for the current state of AFR. Game compatibility in one form or another in recently launched games is the lowest I’ve ever seen it in the last decade, which is rendering multi-GPU setups increasingly useless for improving gaming performance. For that reason, back in November I was seriously considering how I would go about broaching the matter with RTG; how to let them know point blank (and before I even reviewed the card) that Gemini was going to fare poorly if reviewed as a traditional high-performance video card. That isn’t the kind of conversation I normally have with a manufacturer, and it’s rarely a good thing when I do.
This is why as awkward as it’s going to be for RTG to launch a dual-GPU 28nm video card in 2016, that I’m relieved that RTG has pushed back the launch of the card. Had RTG launched Gemini this year as a standard gaming card, they would have run straight into the current problems facing AFR. Instead by delaying it to 2016 and focusing on VR – one of the only use cases that still consistently benefits from multi-GPU setups – RTG gets a chance to salvage their launch and their engineering efforts. There’s definitely an element of making the most of a bad situation here, as RTG is going to be launching Gemini in the same year we finally expect to see FinFET GPUs, but it’s going to be the best course of action they can take at this time.
The Current State of Multi-GPU & AFR
I think it’s fair to say that I am slightly more conservative on multi-GPU configurations than other PC hardware reviewers, as my typical advice is to hold-off on multi-GPU until you’ve exhausted single GPU performance upgrades. In the right situations multi-GPU is a great way to add performance, offering performance greater than any single GPU, but in the wrong scenarios it can add nothing for performance, or worse it can drive performance below that of a single GPU.
The problem facing RTG (and NVIDIA as well) is that game compatibility with alternate frame rendering – the heart of SLI and CrossFire – is getting worse and worse, year by year. In preparing for the Gemini review I began looking at new games, and the list of games that came up with issues was longer than ever before.
| AFR Compatibility (Fall 2015) | |||
| Game | Compatibility | ||
| Batman: Arkham Knight | Not AFR Compatible | ||
| Just Cause 3 | Not AFR Compatible | ||
| Fallout 4 | 60fps Cap, Tied To Game Sim Speed | ||
| Anno 2205 | Not AFR Compatible | ||
| Metal Gear Solid V: The Phantom Pain | 60fps Cap, Tied To Game Physics | ||
| Star Wars Battlefront | AFR Compatible | ||
| Call of Duty: Black Ops III | AFR Compatible | ||
Out of the 7 games I investigated, 3 of them outright did not (and will not) support multi-GPU. Furthermore another 2 of them had 60fps framerate caps, leading to physics simulation issues when the cap was lifted. As a result there were only two major fall of 2015 games that were really multi-GPU ready: Call of Duty: Black Ops III and Star Wars Battlefront.
I’ll first start things off with the subject of framerate caps. As far as framerate caps go, while these aren’t a deal-breaker for mutli-GPU use, as benchmarks they’re not very useful. But more importantly I would argue that the kind of gamers investing in a high-end multi-GPU setup are also the kind of gamers that are going to want higher framerates with 60fps. Next to 4K gaming, the second biggest use case for multi-GPU configurations is to enable silky-smooth 120Hz/144Hz gaming, something that has been made far more practical these days thanks to the introduction of G-Sync and Freesync. Unfortunately even when you can remove the cap, in the cases of both Fallout 4 and Metal Gear Solid V the caps are tied to the games’ simulations, and as a result removing the cap can break the game in minor ways (MGSV’s grenades) or major ways (Fallout 4’s entire game speed). Consequently multi-GPU users are left with the less than palatable choice of limiting the usefulness of their second GPU, or breaking the game in some form.
But more concerning are the cases where AFR is outright incompatible. I touched upon this a bit in our DX12 Ashes article, that games are increasingly using rendering methods that are either inherently AFR incompatible, or at best are so difficult to work around that the development time and/or performance gains aren’t worth it. AFR incompatible games aren’t a new thing, as we’ve certainly had those off and on for years now – but I cannot recall a time where so many major releases were incompatible.
The crux of the issue is that game engines are increasingly using temporal reprojection and similar techniques in one form or another in order to create more advanced effects. The problem with temporal reprojection is, as implied by the name, it requires reusing data from past frames. For a single GPU setup this is no problem and it allows for some interesting effects to be rendered with less of a performance cost than would otherwise be necessary. However this is a critical problem for multi-GPU setups due to the fact that AFR means that while one GPU is still rendering frame X, the other GPU needs to start rendering frame X+1.


Frame interdependency problems like this have been at the heart of a lot of AFR issues over the years, and a number of workarounds have been developed to make AFR continue to work, typically at the driver level. In easier cases the cost is that there is some additional synchronization required, which brings down the performance gains from a second GPU. However in harder cases the workarounds can come with a higher performance hit (if the problem can be worked around at all), to the point where additional GPUs aren’t an effective means to improve performance.
Ultimately the problem is that in the short-to-mid run, these kinds of issues are going to get worse. Developers are increasingly using AFR-unfriendly rendering techniques, and in this age of multiplatform releases where big-budget AAA games are simultaneously developed for two consoles and the PC, PC users are already a minority of sales, and multi-GPU users are a smaller fraction still. Consequently from a developer’s perspective – one that by the numbers needs to focus on consoles first and the PC second – AFR is something of a luxury that typically cannot come before creating an efficient renderer for the consoles.
Which is not to say that AFR is doomed. DirectX 12’s explicit multi-adapter modes are designed in part to address this issue by giving developers direct control over how multiple GPUs are assigned work and work together in a system. However it is going to take some unknown amount of time for the use of DirectX 12 in games to ramp up – with the delay of the Fable Legends the first DX12 games will not be released until 2016 – so until that happens we’re left with the status quo of DirectX 11 and driver-assisted AFR. And that ultimately means that 2015 is a terrible time to launch a product heavily reliant on AFR.

Virtual Reality: The Next Great Use Case for Multi-GPU
That brings me to the second point of today’s analysis, which is what one possible future for multi-GPU setups may be. If AFR is increasingly unreliably due to frame interdependency issues, then if multi-GPU configurations are going to improve performance, then there needs to be a way to use multiple GPUs where frames are minimally dependent on each other. As it turns out, stereoscopic virtual reality is just such a use case.
In its most basic implementation, stereoscopic VR involves rendering the same scene twice: once for each eye (view), with the position of the camera slightly offset to mimic how human eyes are separated. There are a number of optimizations that can be done here to reduce the workload, but in the end many parts of a scene need to be completely re-rendered because the second view can see things (or sees things slightly differently) than the first view.
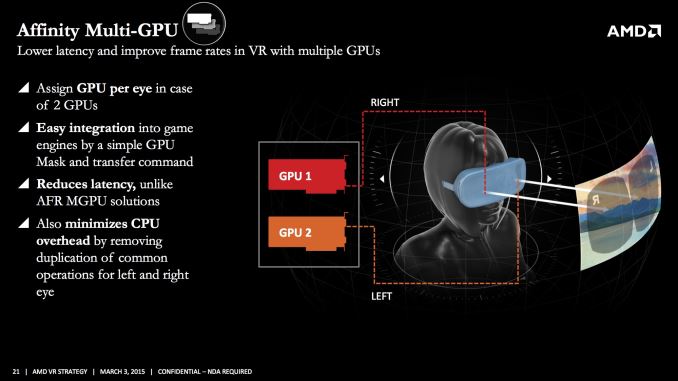
The beauty of stereoscopic rendering as far as multi-GPU is concerned is that because each view is rendering the same scene, there’s little-to-no interdependency between what each view is doing; one view doesn’t affect the other. This means that assigning a GPU to each view is a relatively straightforward operation. And if rendering techniques like temporal reprojection are in use, those again are per-view, so each GPU can reference its past frame in a single-GPU like manner.
At the same time because VR requires rerendering large parts of a frame twice, coupled with the need for low latency it has very high performance requirements, especially if you want to make the jump to VR without significantly compromising on image quality. The recommended system requirements for the Oculus Rift are a Radeon R9 290, a GeForce GTX 970, or equivalent. And if users want better performance or developers want better looking games, then a still more powerful setup is required.
This, in a nutshell, is why VR is the next great use case for multi-GPU setups. There is a significant performance need, and VR rendering is much friendlier to multi-GPU setups. RTG and NVIDIA are in turn both well aware of this, which is why both of them have multi-GPU technologies in their SDKs, Affinity Multi-GPU and VR SLI respectively.
Gemini: The Only Winning Move Is To Play VR
Finally, bringing this back to where I began, we have RTG’s Gemini. If you go by RTG’s statements, they have been planning to make Gemini a VR card since the beginning. And truthfully I have some lingering doubts about this, particularly because the frontrunner VR headset, the Oculus Rift, was already had a Q1’16 launch schedule published back in May, which was before AMD’s event. But at the same time I will say that RTG was heavily showing off VR at their Fiji launch event in June, and the company had announced LiquidVR back in March.

Regardless of what RTG’s original plans were though, I believe positioning Gemini as a video card for VR headsets is the best move RTG can make at this time. With the aforementioned AFR issues handicapping multi-GPU performance in traditional games, releasing Gemini now likely would have been a mistake for RTG from both a reviews perspective and a sales perspective. There will always be a market for multi-GPU setups, be it multiple cards or a singular multi-GPU card, but that market is going to be far smaller if AFR compatibility is poor, as multi-GPU is a significant investment for many gamers.
As for RTG, for better and for worse at this point they have tied Gemini’s future to the actions of other companies, particularly Oculus and HTC. The good news is that even with the most recent delay on the HTC Vive, both companies appear to be ramping up for their respective releases, with word coming just today that game developers have started receiving finalized Rift units for testing. Similarly, both companies are now targeting roughly the same launch window, with the Rift set to arrive in Q1’16 (presumably late in the quarter), and the Vive a month later in April. The risk then for RTG is whether these units arrive in large enough numbers to help Gemini reach RTG’s sales targets, or if the ramp-up for VR will bleed over into what’s expected to be the launch of FinFET GPUs. As is typically the case, at this point only time will tell.
Read More ...
Club3D Releases Their DisplayPort 1.2 to HDMI 2.0 Adapter: The Real McCoy

But before we get too far ahead of ourselves, perhaps it's best we start with why these adapters are necessary in the first place. While 4K TVs are becoming increasingly prevalent and cheap, it's only in the last 18 months that the HDMI 2.0 standard has really hit the market, and with it the ability to drive enough bandwidth for full quality uncompressed 4K@60Hz operation. Somewhat frustrating from a PC perspective, PCs have been able to drive 4K displays for some time now, and the de facto PC-centric DisplayPort standard has offered the necessary bandwidth for a few years, since DisplayPort 1.2. However with DisplayPorts almost never appearing on TVs, there have been few good options to drive 4K TVs at both full quality and 60Hz.
An interim solution - and where some of Club3D's promotional headaches come from - has been to use slower HDMI 1.4 signaling to drive these displays, using Chroma Subsampling to reduce the amount of color information presented, and as a result reducing the bandwidth requirements to fit within HDMI 1.4's abilities. While chroma subsampling suffices in movies and television, as it has for decades, it degrades desktop environments significantly, and can render some techniques such as subpixel text rendering useless.
Meanwhile HDMI 2.0 support has been slow to reach PC video cards. NVIDIA offered it on the high-end the soonest with the Maxwell 2 family - though taking some time to trickle down to lower price HTPC-class video cards - while AMD missed out entirely as their initial plans for HDMI 2.0 were scratched alongside any planned 20nm GPUs. Thankfully PC video cards have supported DisplayPort 1.2 for quite some time, so DisplayPort to HDMI adapters were always an option.
However early DisplayPort 1.2 to HDMI 2.0 adapters were in reality using HDMI 1.4 signaling and chroma subsampling to support 4K@60Hz at reduced image quality. As the necessary controllers were not yet on the market this was making the best of a bad situation, but it was not helped by the fact that many of these adapters were labeled HDMI 2.0 without supporting HDMI 2.0's full bandwidth. So with the release of the first proper HDMI 2.0 adapters, this has led to some confusion.

And that brings us to Club3D's DisplayPort 1.2 to HDMI 2.0 adapter, the first such full HDMI 2.0 adapter to reach the market. Club3D's adapter should allow any DP 1.2 port to be turned into an HDMI 2.0 port with full support for 4K60p with full image quality 4:4:4 chroma subsampling. After the releases of pseudo-HDMI 2.0 adapters over the last several months, this is finally the real McCoy for HDMI 2.0 adapters.
The key here today is that unlike those early pseudo-2.0 adapters, Club3D's adapter finally enables full HDMI 2.0 support with video cards that don't support native HDMI 2.0. This includes AMD's entire lineup, pre-Maxwell 2 NVIDIA cards, and Intel-based systems with a DisplayPort but not an HDMI 2.0 LS-Pcon. In fact, AMD explicitly stated support for DP 1.2 to HDMI 2.0 dongles in their recent driver update, paving the way to using this adapter with their cards.
While we're covering the specifications, it also bears mentioning that Club3D's adapter also supports HDCP 2.2. Though as HDCP 2.2 is an end-to-end standard this means that the host video card still needs to support HDCP 2.2 to begin with, as Club3D's adapter simply operates as a repeater. As a result compatibility with 4K content on older cards will be hit and miss, as services like Netflix require HDCP 2.2 for their 4K content.
Finally, Club3D will be offering two versions of the adapter: a full size DisplayPort version that should work with most desktop video cards, and a Mini DisplayPort version for laptops and all other video cards. And with a roughly $30 asking price listed today it is an attractive option when it is otherwise unreasonable to replace a video card with one that provides HDMI 2.0 in its place.
Read More ...
G.Skill Introduces 64GB DDR4-3200 Memory Kits

G.Skill’s new 16GB DDR4 memory modules are rated to function at 3200 MTs with CL14 14-14-35 or CL15 15-15-35 latency settings at 1.35V voltage, which is higher than industry-standard 1.2V. The modules are based on G.Skill’s printed circuit boards designed for high clock-rates as well as Samsung’s 8Gb memory chips made using 20nm fabrication technology. Such DRAM devices offer both high capacity as well as high frequencies. The new modules will be sold as 32GB and 64GB memory kits under Trident Z and Ripjaws V brands. Both product families come with efficient aluminum heat spreaders.

The new 16GB DDR4 memory modules from G.Skill feature XMP 2.0 profiles in their SPD (serial presence detect) chips, hence, can automatically set maximum clock-rates on supporting platforms.
G.Skill officially claims that the new 16GB memory modules were validated on the Intel Core i7-6700K central processing unit and the ASUS Z170 Deluxe motherboard. Nonetheless, the new quad-channel 64GB kits consisting of four modules should also be compatible with advanced Intel X99-based motherboards running multi-core Intel Core i7 “Haswell-E” processors thanks to XMP 2.0 technology.

Earlier this year G.Skill demonstrated a 128GB DDR4 memory kit — consisting of eight 16GB modules — running at DDR4-3000 with CL14 14-14-35 timings on the Intel Core i7-5960X processor and the ASUS Rampage V Extreme motherboard.
It is not an easy task to build high-capacity memory modules (e.g., 16GB, 32GB, etc.) capable of working at high frequencies. Server-class registered DIMMs use over 16 memory ICs (integrated circuits) or specially packaged memory chips along with buffers that enable flawless operation of such modules. RDIMMs work at default frequencies, but can barely be overclocked. Previous-generation 8Gb memory chips produced using thicker manufacturing technologies were moderate overclockers. Samsung’s 8Gb memory chips can operate at high clock-rates and are used to build high-capacity memory modules for PCs and servers.

G.Skill’s 64GB DDR4 kit rated to operate at DDR4-3200 with CL15 15-15-35 timings will cost $499.99 in the U.S. The 64GB DDR4-3200 kit with CL14 14-14-34 latency settings will be priced at $579.99.



Read More ...
HP Z27q Monitor Review: Aiming For More Pixels
Almost a year ago, we reviewed the HP Z27x monitor, which was a 27-inch display capable of covering a very wide gamut. It had a reasonable 2560x1440 resolution, which was pretty common for this size of display. But at CES 2015, HP announced the HP Z27q monitor, which takes a step back on gamut and manageability, but takes two steps forward with resolution. The HP Z27q is a '5K’ display, which means it has an impressive 5120x2880 resolution. This easily passes the UHD or '4K' levels which are becoming more popular. The HP Z27q is one of a handful of 5K displays on the market now, and HP came in with a pretty low launch price of $1300. When I say pretty low, it’s of course relative to the other 5K displays in the market, but it undercuts the Dell UP2715K by several hundred dollars, even today.
Read More ...
NVIDIA Releases 361.43 WHQL Game Ready Driver

There are quite a few resolved issues this time around. The first of note is an issue with hot unplugging a display from an output, which caused any display hot plugged in afterward to be ignored. There were also issues with players of Star Wars Battlefront running SLI enabled systems experiencing lag after updating the driver to 359.06. Lastly was an issue covered over at PC Perspective a couple of months ago. Where Maxwell based cards (GM20x) were found guilty of rising from idle clock speeds to keep up with the output bandwidth required for refresh rates above 120Hz, which led to more power draw and more noise from the system.
This driver update is also the first release under the R361 branch. As a major version change this update carries a larger number of changes than the usual updates we see. Along with the resolved issues from earlier we also have some notable feature changes to the drivers this time around. First on the list is added WDDM 2.0 support for Fermi based GPU’s. Unfortunately, WDDM 2.0 is only enabled for single GPU setups. SLI users will have to wait a little longer. This is also a good time to note that DX12 support for Fermi is not yet enabled, through will come in a future update (more on this later today).
With Fermi out of the way professional users may be intrigued to hear that through GameWorks VR 1.1 NVIDIA has enabled VR SLI support for OpenGL. Which during NVIDIA’s internal testing led to a claimed 1.7x scaling from one GPU to two. While obviously a case of diminishing returns, that is still a large enough gap in performance to allow much more complexity in one’s workflow or make a job with unbearable performance jump to a much more pleasant framerate.
Anyone interested can download the updated drivers through GeForce Experience or on the NVIDIA driver download page.
Read More ...
Host-Independent PCIe Compute: Where We're Going, We Don't Need Nodes

The CPU handles the networking transfer and when combined with the south bridge, manages the IO and other features. Some orientations allow the coprocessors to talk directly with each other, and the CPU part allows large datasets to be held in local host DRAM. However for some compute workloads, all you need is more coprocessor cards. Storage and memory might be decentralized, and adding in hosts creates cost and complexity - a host that seamlessly has access to 20 coprocessors is easier to handle than 20 hosts with one each. This is the goal of EXTOLL as part of the DEEP (Dynamical Exascale Entry Platform) Project.
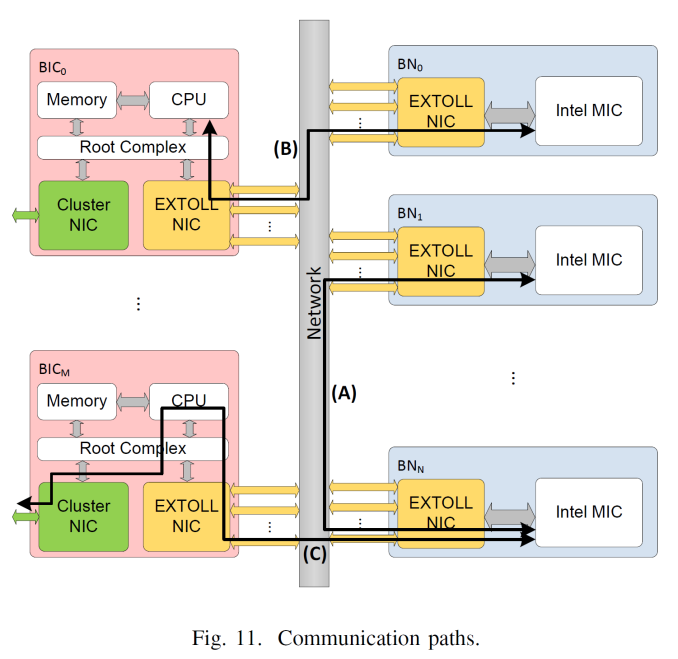
At SuperComputing 15, one of the academic posters on display from Sarah Neuwirth and her team from the University of Heidelberg was around developing the hardware and software stacks to allow for host-independent PCIe coprocessors through a custom fabric. This is theory would allow for compute nodes in a cluster to be split specifically into CPU and PCIe compute nodes, depending on the need of the simulation, but also allows for fail over or multiple user access. All of this is developed through their EXTOLL network interface chip, which has subsequently been spun out into a commercial entity.
A side note - In academia, it is common enough that the best ideas, if they're not locked down by funding terms and conditions, are spun out into commercial enterprises. With enough university or venture capital in exchange for a percentage of ownership, an academic team can hire external experts to make their ideas a commercial product. These ideas either work and fail, or sometimes the intellectual property is sold up the chain to a tech industry giant.
The concept of EXTOLL is to act as a mini-host to initialize the coprocessor but also handles the routing and memory address translation such that it is transparent to all parties involved. On a coprocessor with EXTOLL equipped, it can be connected into a fabric of other compute, storage and host nodes and yet be accessible to all. Multiple hosts can connect into the fabric, and coprocessors in the fabric can communicate directly to each other without the need to move out to a host. This is all controlled via MPI command extensions for which the interface is optimised.
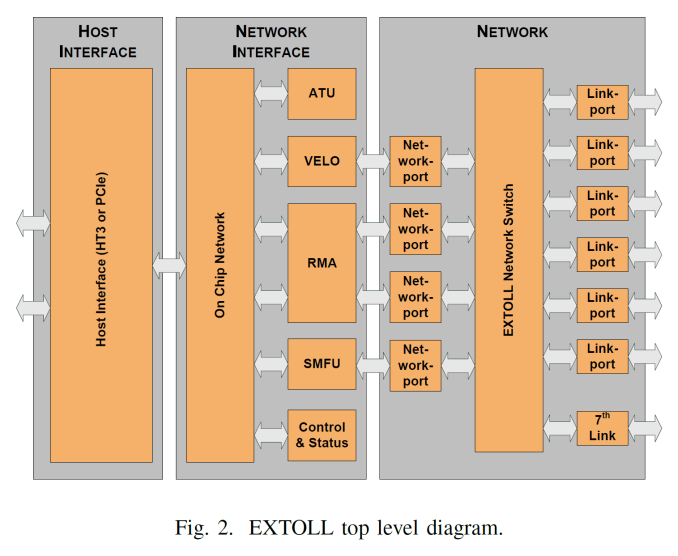
The top level representation of the EXTOLL gives seven external ports supporting cluster architectures up to a 3D Torus plus one extra. The internal switch manages which network port is in use, derived from the translation layer provided by the IP blocks: VELO is the Virtualized Engine for Low Overhead that deals with MPI and in particular small messages, RMA is the Remote Memory Access unit that implements put/get with one-or-zero-copy operations and zero CPU interaction, and the SMFU which is the Shared Memory Function Unit for exporting segments of local memory to remote nodes. This all communicates to the PCIe coprocessor via the host interface which supports both PCIe 3.0 or HyperTransport 3.0.
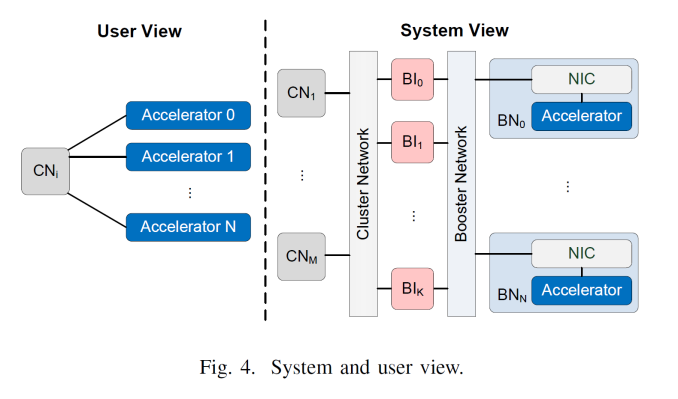
From topology point of view, EXTOLL is not to act as a replacement for a regular network fabric and adds in a separate fabric layer. In the diagram above, the exploded view gives compute and host nodes (CN) offering standard fabric options, booster interface nodes (BI) that have both the standard fabric and EXTOLL fabric, then booster nodes (BN) which are just the PCIe coprocessor and an EXTOLL NIC. With this there can be a 1 to many or a many to many representation depending on what is needed, or in most cases the BI and BN can be combined into a single unit. From the end users perspective, this should all be seamless.
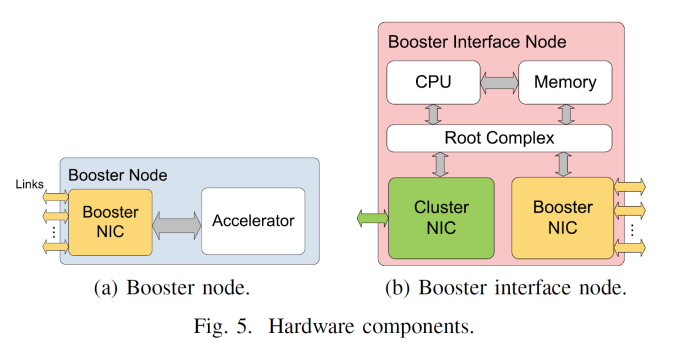
I discussed this and was told that several users could allocate themselves a certain number of coprocessors or the admin can set the limits depending on login or other workloads queued.
On the software side, EXTOLL sits between the coprocessor driver as a virtual PCI layer. This communicates to the hardware through the EXTOLL driver, telling the hardware to perform the required methods of address translation or MPI messages etc. The driver provides the tools to do the necessary translation of PCI commands across its own API.
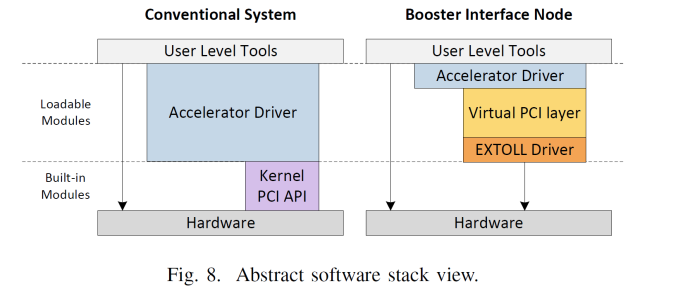
The goal of something like EXTOLL is to be part of the PCIe coprocessor itself, similar to how Omni-Path will be on Knights Landing, either as a custom IC on the package or internal to the die. That way the EXTOLL connected devices can be developed into devices in a different physical format to the standard PCIe coprocessor cards, perhaps with integrated power and cooling to make design more efficient. The first generation of this was built on an FPGA and used as an add-in to a power and data only PCIe interface. The second generation is similar, but this time has moved out into a 65nm TSMC based ASIC, reducing power and increasing performance. The latest version is the Tourmalet card, using upgraded IP blocks and featuring 100 GB/s per direction and 1.75 TB/s switching capacity.

Current tests with the 2nd generation, the Galibier, and a dual node design gave LAMMPS (a biochemistry library) speed up of 57%.
The concept of host-less PCIe coprocessors is one of the next steps towards exascale computing, and EXTOLL are now straddling the line between commercial products and presenting their research as part of academic endeavours, even though there is the goal of external investment, similar to a startup. I am told they already have interest and proof of concept deployment with two partners, but this sort of technology needs to be integrated into the coprocessor itself - having something the size of a motherboard with several coprocessors talking via EXTOLL without external cables should be part of the endgame here, as long as power and cooling can be controlled. The other factor is ease of integration with software. If it fits easily into current MPI based codes and libraries, on C++ and FORTRAN, and it can be supported as new hardware is developed with new use cases, then it is a positive step. Arguably EXTOLL thus needs to be brought into on of the large tech firms, most likely as an IP purchase, or others will develop something similar depending on patents. Arguably the best person into that position will be Intel with its Omni-Path, but consider that FPGA vendors have close ties to Infiniband, so there could be potential there.
Relevant Paper: Scalable Communication Architecture for Network-Attached Accelerators
Read More ...
The Angelbird Wings PX1 M.2 Adapter Review: Do M.2 SSDs Need Heatsinks?
The M.2 form factor has quickly established itself as the most popular choice for PCIe SSDs in the consumer space. The small size easily fits in to most laptop designs, and the ability to provide up to four lanes of PCI Express accommodates even the fastest SSDs. By comparison, SATA Express never caught on and never will due to its two-lane limitation. And the more recent U.2 (formerly SFF-8639) does have traction, but has seen little adoption in the client market.
Meanwhile, although M.2 has its perks it also has its disadvantages, often as a consequence of space. The limited PCB area of M.2 can constrain capacity: Samsung's single-sided 950 Pro is only available in 256GB or 512GB capacities while the 2.5" SATA 850 Pro is available in up to 2TB. And for Intel, the controller used in their SSD 750 is outright too large for M.2, as it's wider than the most common M.2 form factor (22mm by 80mm). Finally and most recently, as drive makers have done more to take advantage of the bandwidth offered by PCIe, a different sort of space limitation has come to the fore: heat.
When testing the Samsung SM951 we found that our heavier sustained I/O tests could trigger thermal throttling that would periodically restrict the drive's performance. We also had a brief opportunity to run some of our tests on the SM951 using the heatsink from Plextor's M6e Black Edition. We found that extra cooling made noticeable differences in performance on some of our synthetic benchmarks, but our more realistic AnandTech Storage Bench tests showed little or no change. But other than the quick look at the SM951, we haven't had the chance to do a thorough comparison of how cooling affects high-performance M.2 drives, until now.
Read More ...
Dell Issues Patch For Content Adaptive Brightness Control On The XPS 13

It was also an issue when trying to calibrate the display. The calibration software first sets a baseline brightness on white (200 nits again is what we use) and then flashes various shades of gray and color to create a profile for the display. Once again, the CABC would get in the way, changing the brightness that the software was expecting.
I think for most people, it would be something that they would notice, but not something that would bother them too much, unless you were doing certain tasks where it would kick in. I am all for power saving features, but anytime you add something like this, you need to have a way to disable it for customers who don’t want it. Luckily Dell is now offering a patch to disable this feature.
At the moment, the only way to get the patch is to contact Dell support. It would be nice if they would just offer it as a link to download, but for the moment this is what we have.
Being able to remove the aggressive CABC fixes one of my biggest issues with the XPS 13, and it was already one of the best laptops of the year. With this fix, it moves up a bit more.
Source: Dell
Read More ...
Available Tags:AMD , HP , NVIDIA , WHQL , Driver , Dell ,
No comments:
Post a Comment